One-shot Dual-arm Imitation Learning
An example multi-stage dual-arm task learned from a single demonstration using ODIL. The robot grasps the handle of a rice paddle, rearranges it, hands it over, and then inserts it into the holder of a rice cooker.
Abstract
We introduce ODIL, a novel approach to one-shot dual-arm imitation learning that enables dual-arm robots to learn precise and coordinated everyday tasks from just a single human demonstration. ODIL parametrizes a coordinated trajectory from this demonstration using a novel dual-arm coordination paradigm, and introduces a three-stage deep match visual servoing (3-VS) controller for precise and robust state estimation. This is achieved without the need for prior knowledge of tasks or objects, precise camera calibration, or additional data collection and training. Our method has been tested on a real-world dual-arm robot, demonstrating state-of-the-art performance across six precise and coordinated tasks in both 4-DoF and 6-DoF settings, and showing robustness in the presence of distracting objects and partial occlusions.
Method
Video
3-VS Controller
At the core of ODIL is a three-stage deep match visual servoing (3-VS) controller, that combines recent advances in deep feature matching with traditional analytic visual servoing techniques. It utilizes both an eye-to-hand global camera and an eye-in-hand wrist camera for precise and robust state estimation, while allowing for arbitrary initial robot configurations.
Dual-arm co-ordination Paradigm
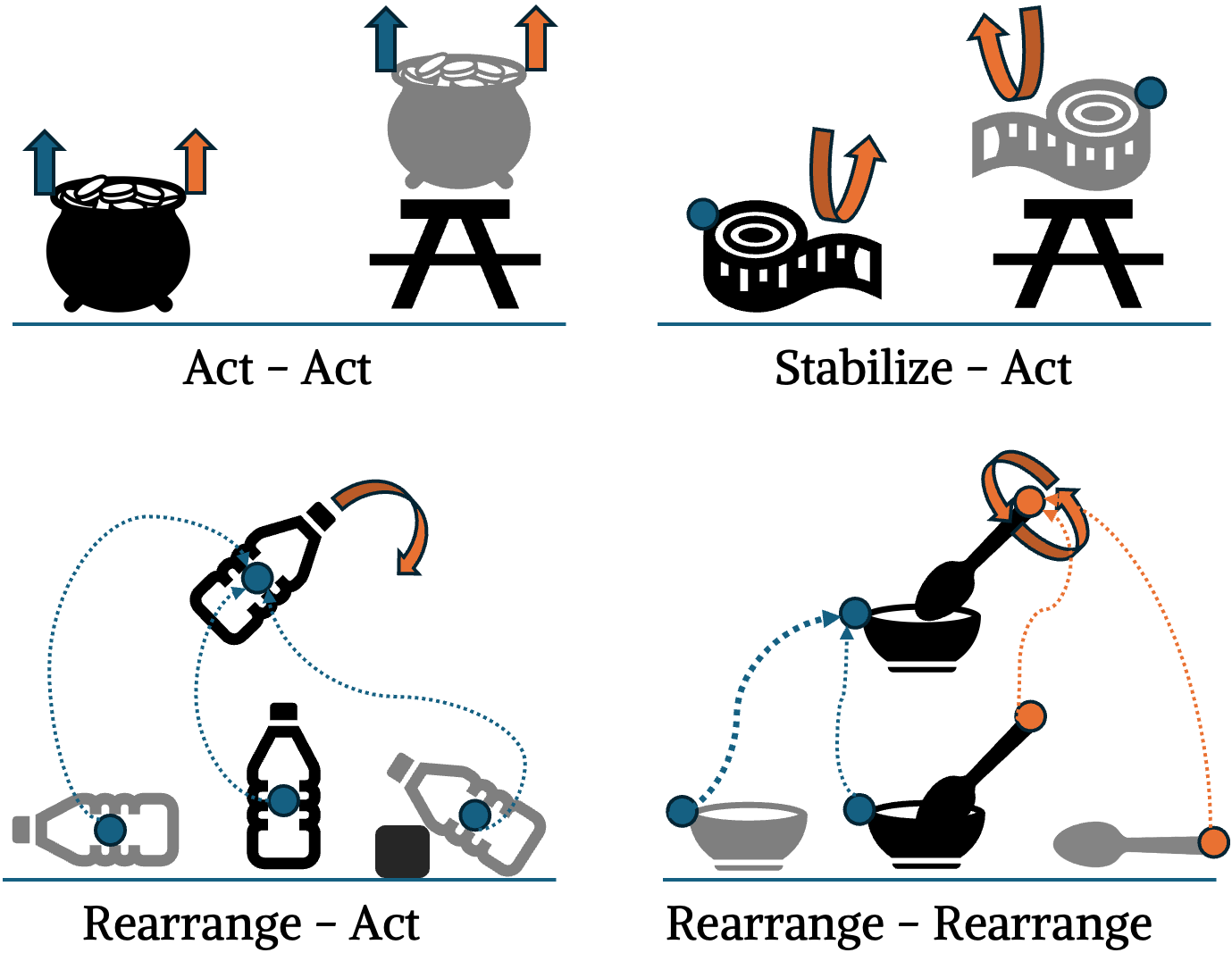
Inspired by the BUDS framework, we introduce a dual-arm coordination paradigm based on three arm primitives: act, stabilize, and rearrange.
- Act: Arms interact with objects with tailored velocity.
- Stabilize: Arms hold objects steady for stability.
- Rearrange: Arms reposition objects between poses.
These primitives support four coordination strategies: Act-Act, Stabilize-Act, Rearrange-Act, and Rearrange-Rearrange. We state-parameterize coordinated trajectories from human demonstrations and deploy them in novel scenarios.
Evaluation
Robot Results
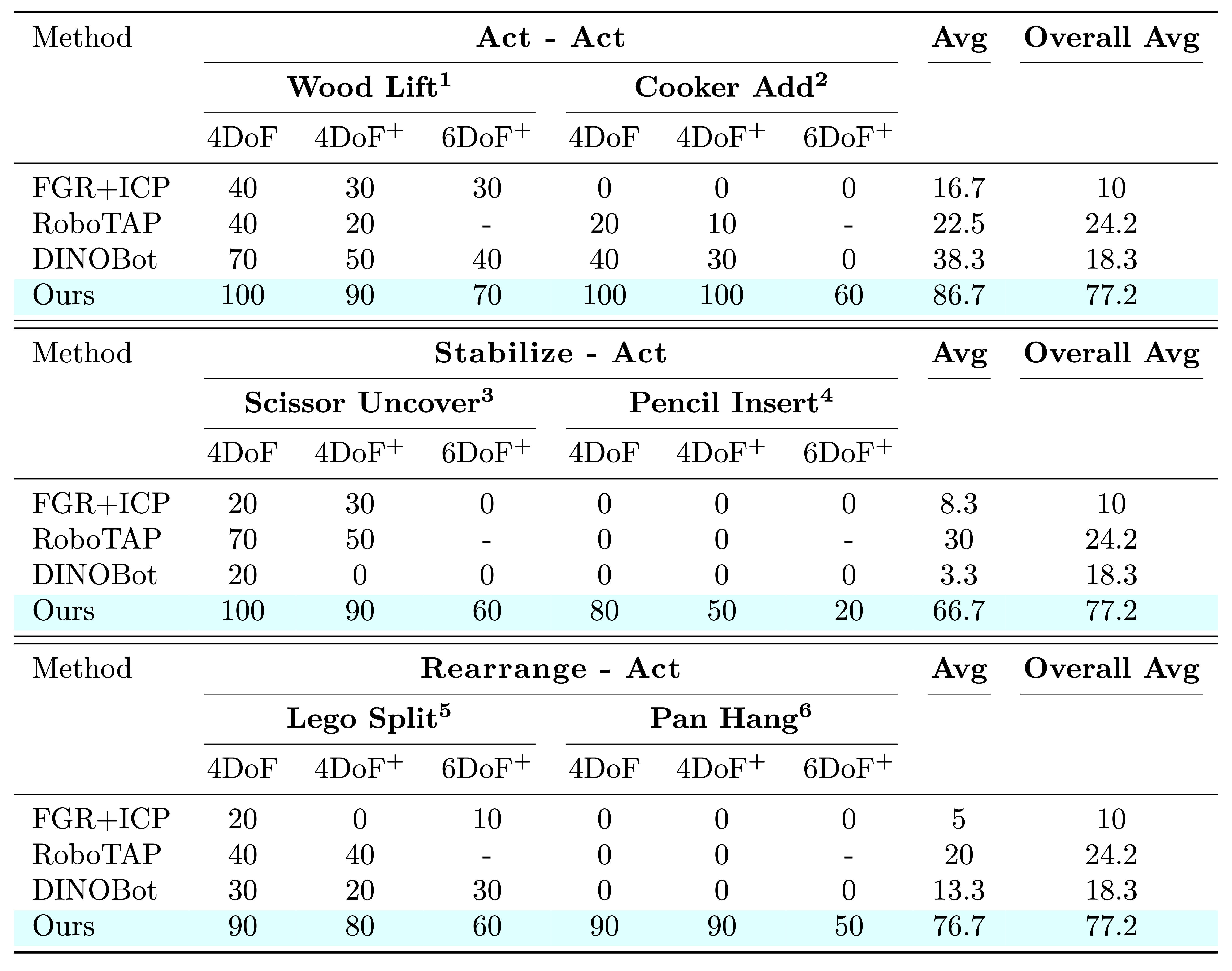
We provided the robot with a single demonstration for each of the six precise, coordinated tasks, and then evaluated ODIL's performance across three distinct settings. First, in the 4 DoF setting, with a clear background and 4-DoF object pose changes. Second, in the 4 DoF+ setting, with variations in background, distracting objects, and partial occlusion. Finally, in the 6 DoF+ setting, involving 6-DoF object pose variations on top of the previous conditions. For the 4 DoF experiments, the controller also operated with 4 DoFs, specifically (x, y, z, rz).
Please click on the images below to view the corresponding videos. The currently displayed video is the Wood Lift task.
In each setting, we conducted 10 rollouts, achieving an average success rate of 77.2% across 180 rollouts spanning the 6 tasks, which required three different coordination strategies. Our method significantly outperformed the baselines in all settings.

Qualitative Comparison
We compare our method with state-of-the-art few-shot and one-shot imitation learning approaches that also rely on keypoints, visualizing the results in heavily clustered and occluded scenes below. The bottleneck image appears on the right.

The keypoints were derived from both the bottleneck image and its segmentation mask. Ideally, these keypoints should be applied only to the task-relevant object, ignoring distracting objects and partial occlusions, while maintaining temporal consistency. Our method demonstrated the best performance in achieving these objectives, as shown in the videos above.
In our method's visualization, the orange represents keypoint matches from SIFT+LightGlue (for viewpoint robustness), the green indicates inliers from SuperPoint+LightGlue (for illumination robustness) on a virtual plane attached to the object, and the magenta applies the bottleneck mask directly to the current images. For more details, please refer to our paper.
Failure Modes
We summarized the main failure modes below:
- Lighting. Tasks requiring high precision (1–2 mm) may fail due to inconsistent lighting conditions.
- Occlusion. The gripper-held pencil and spatula significantly obstruct the sharpener, preventing successful matches.
- Collision. Despite successfully opening the lid, the placing arm collides with the rice cooker when executing a 90-degree rotated trajectory from the demonstration.
- Singularity. Operating near joint limits causes the robot to trigger emergency safety stops.
- 3D Rotation. LightGlue struggles to generate quality matches for large 3D object rotations, as it has been trained primarily on upright images.
- Slippage. The handle slips during pan manipulation due to insufficient gripper friction.

Q&A
How well does Stage 1 perform on its own?
Stage 1 functions as an open-loop state estimator using a global camera, ensuring initial visibility when the object may not be detected by the wrist camera. However, relying solely on Stage 1 results in a low success rate of just 10% compared to closed-loop state estimators. It also struggles with 6DoF object pose variations and is highly sensitive to camera calibration accuracy.
What is the role of Stage 2?
Stage 2 acts as a transition phase, gradually shifting confidence from the global camera to the wrist camera. This avoids abrupt switches and enhances the smoothness of the approach trajectory. Additionally, we leverage rotation-invariant feature matchers to improve robustness and increase the overlap between the bottleneck and the current image for Stage 3.
Why not use Stage 2 throughout?
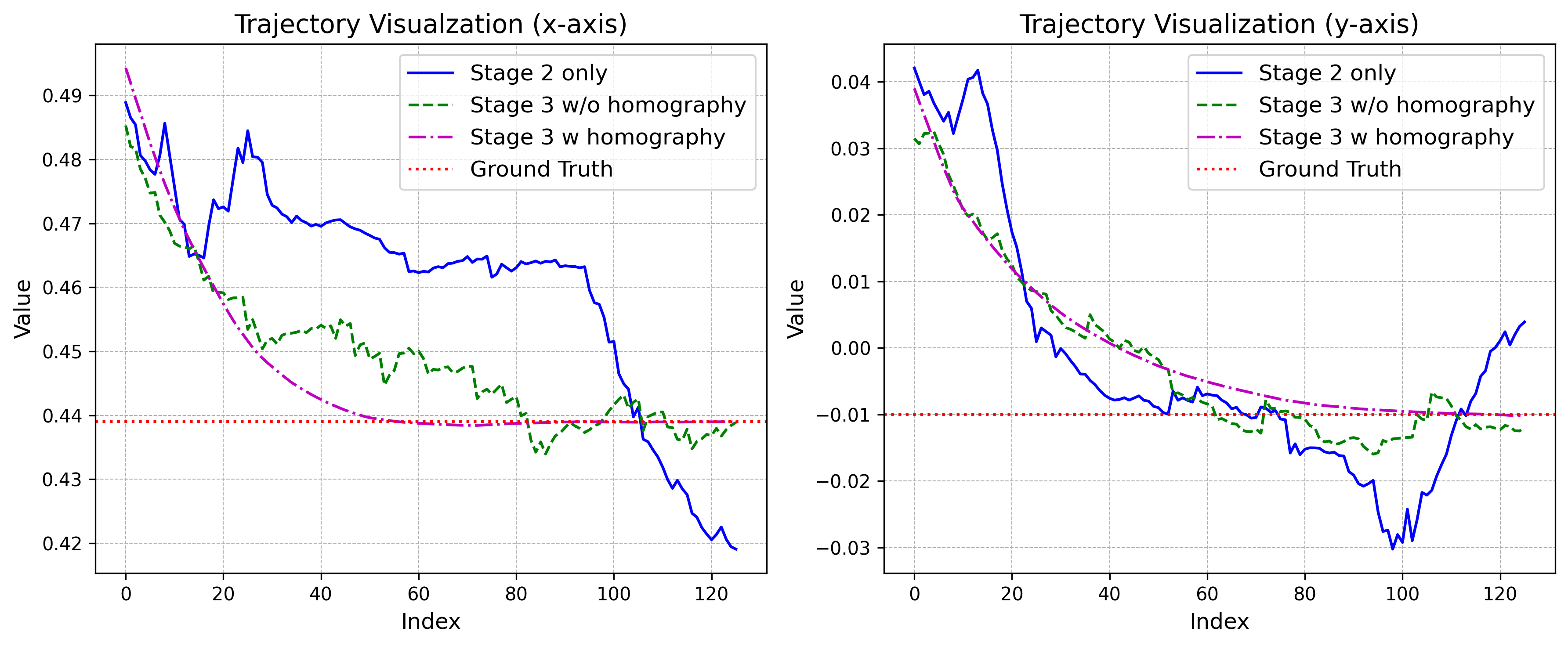
The figure below compares trajectories from three controller variants during real-world rollouts under small object rotations. Stage 3 with homography demonstrates superior performance, asymptotically converging to the ground truth. In contrast, Stage 2 exhibits divergence due to numerical instabilities, estimation noise, and hand-eye calibration errors. While Stage 3 without homography (weighted averaging) achieves convergence, it suffers from jerky movements and oscillations caused by matching uncertainties that weighted averaging fails to mitigate. The homography-based approach overcomes these issues by leveraging robust MAGSAC++ estimators to compute a virtual plane attached to the object, reducing noise and rejecting outliers. These results validate our choice of homography-based 2½D visual servoing [1] [2] for the final alignment stage.
BibTeX
@article{Wang2025OneShotDI,
title={One-Shot Dual-Arm Imitation Learning},
author={Yilong Wang and Edward Johns},
journal={2025 IEEE International Conference on Robotics and Automation (ICRA)},
year={2025},
pages={5660-5668},
}